
Также известный как паук-бот или паук, веб-краулер — это бот, который индексирует содержимое веб-сайта в поисковых системах и организует его в результаты поиска. После загрузки веб-страницы в Интернет веб-краулер узнает, о чем она, чтобы, когда понадобится информация, ее можно было легко извлечь.
Так что же такое краулер и зачем владельцам веб-сайтов нужно знать, что это такое?
- Что такое паук-сети и как он работает?
- Веб-сканирование против веб-скрапинга
- Почему веб-сканеры важны для SEO?
- Как веб-сканирование влияет на SEO?
- Как узнать, проиндексирован ли ваш сайт
- Что такое бюджет сканирования?
- Руководство по управлению бюджетом сканирования
- 1) Используйте Robots.Txt
- 2) Уменьшите количество ошибок на вашем сервере
- 3) Уменьшите количество цепочек перенаправлений
- 4) Избегайте дублирования контента
- 5) Используйте ссылки с умом
- 6) Избегайте страниц-сирот
- 7) Используйте HTML
- 8) Увеличьте скорость загрузки страницы
- 9) Контролируйте сканирование и индексацию вашего сайта
- 10) Проверьте, достаточно ли быстро сканируются обновления
- Как остановить сканирование моего сайта ботами
- а) Используйте Robots.txt
- б) HTTP-аутентификация
- c) CAPTCHA
- г) Блокировать IP-адреса
- д) Тег Noindex
- Часто задаваемые вопросы Веб-сканеры
- i) Почему боты Google называются пауками?
- ii) Что является примером веб-сканера?
- iii) Используются ли веб-сканеры для интеллектуального анализа данных?
- Заключительные мысли
Что такое паук-сети и как он работает?

Источник изображения: searchenginejournal.com
Как следует из названия, веб-паук или краулер — это бот, который автоматически получает доступ к веб-сайту и собирает данные с помощью программного обеспечения. Этот процесс известен как сканирование веб-сайта и лежит в основе каждой поисковой системы. Поскольку в Интернете существуют миллиарды наборов данных, боты гарантируют, что пользователь найдет то, что он ищет, индексируя наборы данных.
Процесс сортировки этой информации называется индексированием. Вы когда-нибудь видели индекс книги, где темы в книге организованы в список с номерами страниц для их поиска? Аналогично индексирование в Интернете позволяет боту знать, куда именно вас вести, когда вы ищете тему.
При индексации бот изучает текст, используемый на веб-странице, просматривая ключевые слова и заголовки. Бот также использует мета-описание и мета-заголовок как часть мета-тегов для выполнения поиска. Однако это атрибуты, которые пользователь никогда не увидит. Во время индексации бот может добавить все слова на странице в индекс. Эти слова исключают такие термины, как a, an, the и т. д.
Когда пользователь ищет, бот проходит по его индексу и показывает пользователю наиболее релевантные результаты. Вот почему важно использовать наиболее релевантные ключевые слова при создании контента для вашего веб-сайта.
Бот может сканировать интернет, используя гиперссылки с одной крупной страницы на другую, чтобы извлечь информацию, которая будет в результатах поиска, как только пользователь выполнит поиск в интернете. Например, если страница ссылается на другую страницу с похожим содержанием, боты это учитывают и индексируют такие страницы. После индексации страницы будут извлечены благодаря ссылкам.
Веб-сканирование часто путают с веб-скрапингом. Насколько они отличаются?
Веб-сканирование против веб-скрапинга

Источник изображения: datadeck.com
Веб-сканирование направлено на индексацию и поиск веб-страниц, в то время как веб-скрейпинг — это сбор данных из сети. Веб-скрейпинг извлекает коды, используемые в HTML, и данные в базе данных. После скрапинга бот может скопировать всю информацию веб-сайта в другом месте.
Для владельцев веб-сайтов веб-сканирование является важной частью SEO, которая требует большого внимания . Итак, почему веб-сканеры важны для SEO?
Почему веб-сканеры важны для SEO?

Источник изображения: seozoom.com
Поскольку за индексацию отвечают поисковые роботы, любой, кто хочет, чтобы его веб-страница занимала высокие позиции, должен обращать внимание на то, что ищут поисковые роботы.
Так где же встречаются веб-сканеры и SEO?
Как веб-сканирование влияет на SEO?
Веб-сканеры должны обнаружить и проиндексировать вашу страницу, чтобы другие люди могли ее найти, и сделать вашу страницу легкой для сканирования должно быть одной из ваших стратегий SEO. Сканер необходим для SEO, поскольку он ранжирует веб-страницы от наиболее к наименее релевантным. Чем больше страниц посвящено определенной теме, тем лучше должен быть ваш контент по той же теме, чтобы ваша страница имела высокий рейтинг.
SERP (страница результатов поиска) — это поле битвы, и каждый борется за то, чтобы оказаться на первой странице.
Прежде чем беспокоиться о рейтинге, вам нужно убедиться, что ваш сайт проиндексирован. Как узнать, проиндексирован ли ваш сайт?
Как узнать, проиндексирован ли ваш сайт

Источник изображения: analyticahouse.com
Чтобы узнать, сколько страниц вашего сайта проиндексировано, вы можете воспользоваться простой формулой в Google;
site:домен.com
Например, для компании под названием «Example» этот поиск будет применим;
site:example.com
Теперь, когда мы установили, что для индексации ваш сайт необходимо сканировать, что такое бюджет сканирования?
Что такое бюджет сканирования?

Источник изображения: datanami.com
Бюджет сканирования относится к числу страниц, которые поисковые системы сканируют в любой день. Кроме того, то, сколько раз пауки проходят по вашему домену, также считается вашим бюджетом сканирования.
Количество просканированных страниц зависит от того, насколько хорошо заботятся о страницах, поскольку ботам будет либо легко, либо сложно их сканировать. Например, если на ваших страницах слишком много ошибок или много ненужных ссылок, то будет просканировано меньше страниц, поскольку боты будут откладывать страницы, чтобы просканировать их позже, и это снизит скорость сканирования. Когда ваши сайты сканируются медленнее, это влияет на ваш рейтинг в Google.
Существует множество причин, по которым Google может потребоваться просканировать ваш сайт.
- Если на вашем сайте будут внесены какие-либо изменения, Google придется их отметить.
- Если кто-то упомянул вас в Twitter, ему нужно будет это отметить, и он сделает это с помощью сканирования.
- При создании новой ссылки или URL.
Если у вас большой сайт, вам нужно обратить внимание на то, как происходит сканирование Google, поскольку это может либо ускорить, либо замедлить индексацию ваших страниц.
Руководство по управлению бюджетом сканирования
Источник изображения: bestproxyreviews.com
Если у вас большой сайт с несколькими страницами, боты Google составят список доступных URL-адресов, которые им нужно будет просканировать позже. Боты создают что-то в виде списка дел для сканирования. Если у вас большой сайт, «список» будет длиннее, и его нужно будет быстрее просмотреть. По этой причине вам нужно облегчить краулерам выполнение своей работы эффективно, чтобы ваши страницы индексировались и ранжировались как можно чаще.
Помните, чем больше сканируются ваши страницы, тем быстрее они индексируются.
Вот несколько действий, которые владельцы крупных сайтов могут выполнить для улучшения своего бюджета сканирования.
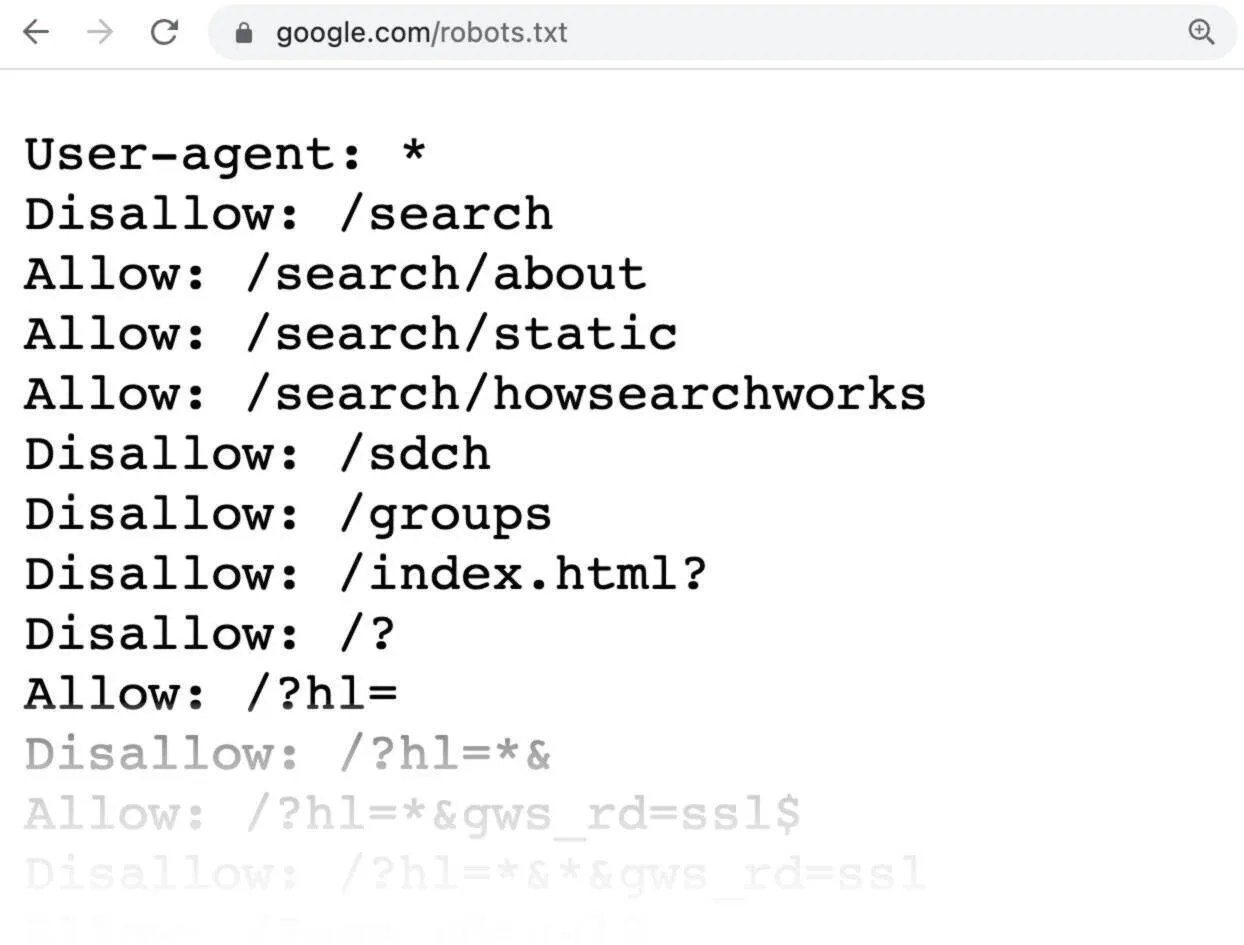
1) Используйте Robots.Txt
Источник изображения: semrush.com
Robots.Txt может быть основным различием между медленной и быстрой индексацией. Robots.Txt помогает вам выбирать, к каким URL-адресам сканеры могут получить доступ, а какие следует избегать. Это упрощает контроль трафика сканеров на вашей странице, вместо того чтобы позволять сканерам иметь дело с большой частью URL-адресов.
Вы можете добавить Robots.Txt самостоятельно, что даст вам полный контроль и сосредоточит сканеры на наиболее релевантных страницах. Есть несколько ограничений, которые идут с Robots.Txt, о которых вам нужно знать.
Во-первых, Robots.Txt может не поддерживаться некоторыми крупными поисковыми системами. К счастью, Google — это все, о чем вам нужно беспокоиться большую часть времени из-за экосистемы вокруг него. Даже когда поисковые системы поддерживают Robots.Txt, есть сканеры, которые могут интерпретировать синтаксис и правила Robots.Txt по-другому. Однако большинство веб-сканеров следуют правилам, установленным Robots.Txt.
Страница может блокировать Robots.Txt и все равно индексироваться, если на нее ссылается другая страница. Один из способов избежать такой ситуации — защитить файлы на сервере паролем, чтобы они не индексировались.
2) Уменьшите количество ошибок на вашем сервере

Источник изображения: xeonbd.com
Коды возврата — это сообщения, которые сервер возвращает программе, показывающие статус запроса. Если обработка запроса не удалась, вы получите код ошибки. Если вы получаете код возврата, отличный от 200 или 301, то на вашем сервере могут быть ошибки. Например, ошибки 404, 400 и 401 — это коды возврата ошибок.
Вы можете просмотреть журнал сервера, чтобы узнать, будут ли у вас коды возврата ошибок или нет. Это важно, поскольку Google Analytics будет просматривать только страницы с кодом возврата 200, что является важной информацией, необходимой для улучшения SEO.
После того как вы определили проблемные коды возврата в журнале сервера, вы можете исправить коды возврата ошибок или перенаправить URL-адреса в другое место с помощью менеджера перенаправлений.
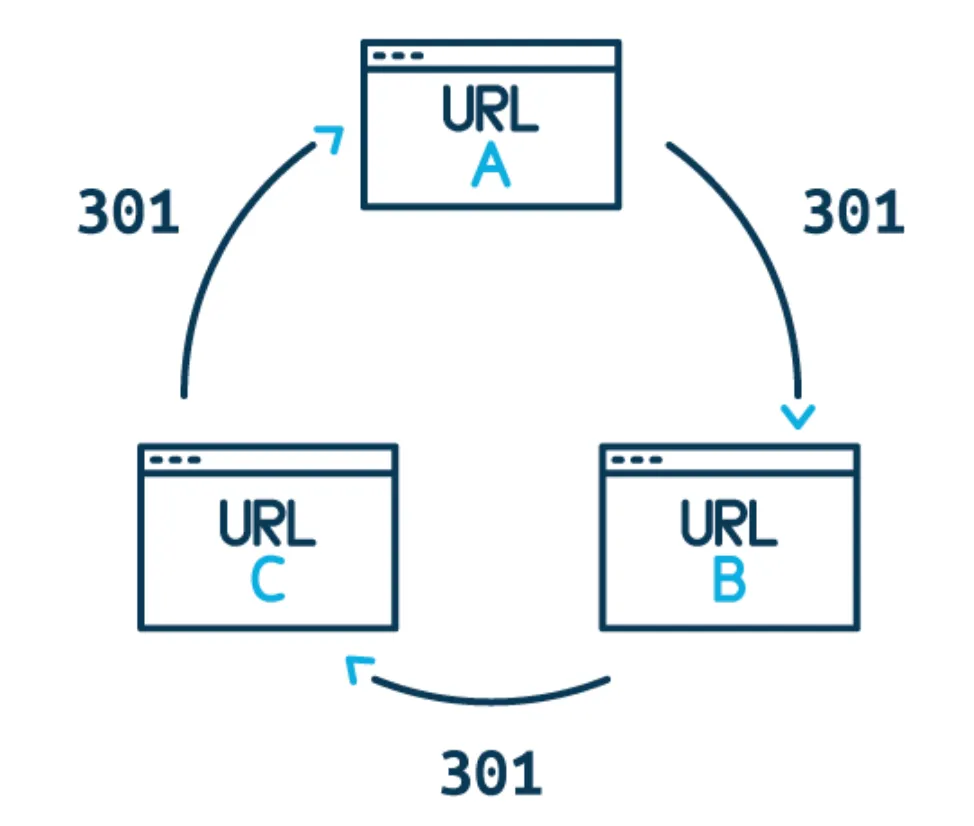
3) Уменьшите количество цепочек перенаправлений
Источник изображения: ventsmagazine.com
Ранее мы обсуждали, какие коды возврата вы можете получить при выполнении поиска. Хотя в вашем журнале сервера должен быть один из кодов возврата 301, они увеличивают время сканирования. Это связано с тем, что как только сканеры замечают перенаправление, они не сканируют его немедленно, а скорее помещают его в «список дел», чтобы сканировать его позже. Это может сократить ваш бюджет сканирования.
4) Избегайте дублирования контента
Google предпочел бы не использовать свои ресурсы для индексации дублирующегося контента. Вот почему важно быть уникальным при публикации контента.
5) Используйте ссылки с умом
Google отдает приоритет сайтам с большим количеством ссылок, указывающих на них. Такие сайты демонстрируют признаки доверия. Вы можете добавить внутренние ссылки, которые, в свою очередь, привлекут внимание Google. Помните, что боты Google следуют по ссылкам, и когда вы используете внутренние ссылки, они будут следовать по этим ссылкам на страницы, которые вам нужно проиндексировать, увеличивая скорость сканирования.
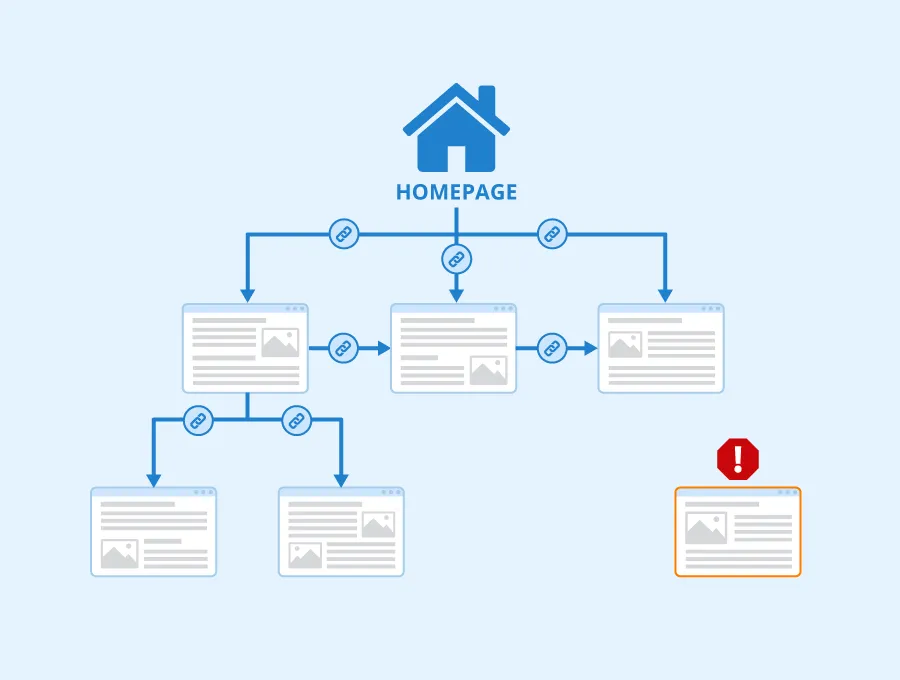
6) Избегайте страниц-сирот
Источник изображения: seobility.net
Страница-сирота — это страница, на которую не указывает ни одна ссылка. Google с трудом находит такую страницу на вашем веб-сервере.
7) Используйте HTML

Источник изображения: oxfordwebstudio.com
Если вы используете Google, лучше использовать HTML на своих сайтах вместо JavaScript. Это связано с тем, что HTML будет сканироваться ботами относительно быстрее, чем JavaScript, который сканируется не так быстро при использовании Google в качестве поисковой системы. Это напрямую влияет на бюджет сканирования сайта.
8) Увеличьте скорость загрузки страницы

Источник изображения: popupsmart.com
Если ваш сайт медленный, бюджет сканирования будет низким. Вы можете сделать свой сайт быстрее, избегая больших изображений или громоздких ресурсов. Скорость вашего сайта должна быть достаточно адекватной, чтобы своевременно отвечать на запросы.
9) Контролируйте сканирование и индексацию вашего сайта

Источник изображения: agency90.fr
Существуют методы, которые вы можете использовать, чтобы узнать, происходит ли сканирование на вашем сайте. Во-первых, вы можете проверить статус вашего URL в индексе Google. Если страница не была проиндексирована, вы можете узнать причину, проверив, индексируется ли страница.
Если вам нужно, чтобы URL индексировался Google, вы можете подать запрос и индексировать его. Кроме того, вы можете устранить неполадки с отсутствующими страницами или даже увидеть, что бот видит на вашей странице, запросив визуализированную версию.
10) Проверьте, достаточно ли быстро сканируются обновления

Источник изображения: onely.com
Вы можете проверить отчет о статистике сканирования, чтобы увидеть историю сканирования на вашем сайте. Вы можете увидеть количество сделанных запросов, когда они были сделаны, как ответил сервер и любые проблемы, возникшие на вашей странице.
Эта информация также поможет вам определить, возникают ли у Googlebot проблемы с доступностью вашего сайта.
Как остановить сканирование моего сайта ботами
Могут быть случаи, когда вы захотите остановить сканирование вашего сайта ботом. Например, когда вы все еще работаете над своим сайтом, обновляете его, вносите изменения или архивируете его, ботам не нужно сканировать страницы. Итак, как вы можете остановить сканирование вашего сайта ботами?
а) Используйте Robots.txt
Как обсуждалось ранее, robots.txt контролирует поведение поисковых роботов на вашем сайте, сообщая им, какие сайты сканировать, а какие игнорировать.
б) HTTP-аутентификация
Для HTTP-аутентификации требуется ввести имя пользователя и пароль перед выполнением любых действий на вашем сайте, включая сканирование.
c) CAPTCHA
CAPTCHA — это метод, используемый для различения людей и роботов. Он требует от пользователя выполнения простой задачи, которую роботы обычно не могут выполнить. Таким образом, CAPTCHA может отпугивать краулеров.
г) Блокировать IP-адреса
Если определенный IP-адрес направляет нежелательный трафик на ваш сайт, вы можете заблокировать его. Трафик часто включает ссылки, которые в большинстве случаев указывают на вас ботами.
д) Тег Noindex
Noindex — это тег, который заставляет Google убрать страницу из результатов поиска. Такая страница будет невидимой, даже если на нее будут ссылаться другие страницы.
Зачем кому-то может понадобиться запрещать ботам сканировать свой сайт?
- Боты могут использовать часть ресурсов сервера вашего веб-сайта, включая пропускную способность и вычислительную мощность.
- Некоторые боты вредоносны. Например, боты предназначены для того, чтобы скрейпить и скопировать контент с вашей страницы.
- Вредоносные роботы могут внедрять спам и вредоносный код на ваш сервер.
- Когда вы все еще работаете над своей страницей, вносите изменения, меняете место назначения контента и обслуживаете свою страницу.
Часто задаваемые вопросы Веб-сканеры
i) Почему боты Google называются пауками?
Большинство пользователей выходят в интернет через всемирную паутину. Поскольку бот ползает по всей «паутине», они формируют образы того, что делают пауки.
ii) Что является примером веб-сканера?
Существуют различные типы краулеров для разных поисковых систем. Например, Bing использует Bingbot, Amazon — Amazonbot, Google — Googlebot, DuckDuckGo — DuckDuckbot и другие.
iii) Используются ли веб-сканеры для интеллектуального анализа данных?
Веб-краулеры могут использоваться для добычи данных, которая представляет собой процесс сбора информации в больших объемах. Данные могут использоваться для изучения закономерностей и поиска взаимосвязей в закономерностях данных.
Заключительные мысли

Источник изображения: crayondata.com
Хотя бюджет сканирования вашего сайта не является единственной причиной повышения вашего рейтинга, он играет важную роль в обеспечении того, чтобы ваши сайты находили и ранжировали. Вам нужно уделить много внимания тому, чтобы сделать вашу страницу оптимальной для сканирования, особенно если вы управляете большими сайтами, чтобы они часто индексировались.
Источник главного изображения: euronews.com







